BioUnfold #18 — Discovery Is a Learning System
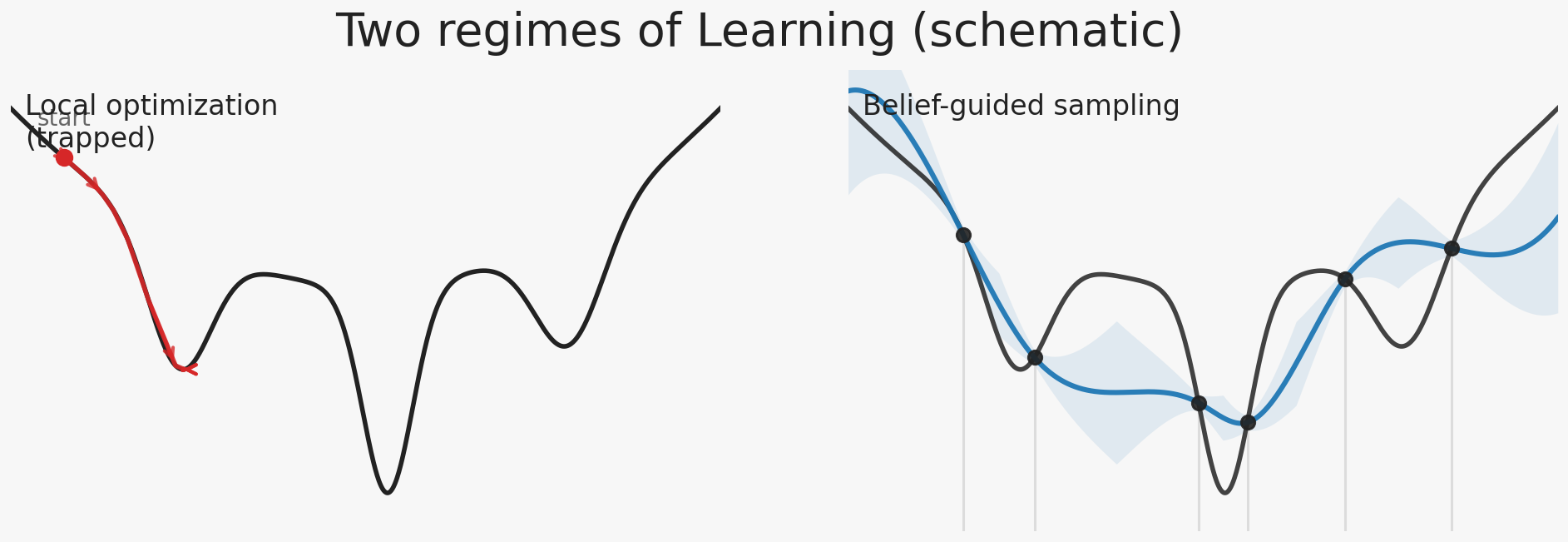
Two regimes of learning
In computation, there are two broad ways to learn about an unknown system.
Most modern machine learning operates in a single regime: local optimization under a fixed objective. Learning proceeds through enormous numbers of cheap, incremental updates guided by dense feedback. Progress comes from repeatedly probing a stable objective landscape and nudging the system toward locally better states. The system can afford to be local because queries are cheap and iteration is effectively unlimited.
Wet discovery does not have this luxury.
Experiments are slow. Queries are expensive. The landscape is only visible through sparse, indirect projections. Local improvement cannot be cheaply tested, reversed, or averaged away. Each step commits the system to a direction.
The second regime is sequential inference and decision-making under uncertainty. The system maintains an explicit hypothesis space and a belief state. Observations update that belief, and actions are chosen by deciding what to sample next, conditioned on what the system currently thinks might be true. Learning is therefore not only about fitting models, but about controlling which evidence the system will generate.
Wet scientific discovery lives almost entirely in this second regime. Every experiment is therefore not only a measurement, but a decision: a choice about what question is worth asking next, given everything that has already been seen.
It is sequential learning under extreme cost, latency, and irreversibility.
How discovery actually learns
In practice, discovery is organized as a sequence of stages:
- Assay development
- Hit discovery
- Hit confirmation and expansion
- Lead optimization
- Preclinical profiling
Each stage defines proxy objectives that can be operationalized. Fixed protocols and readouts are used to filter and reshape an initial space of compounds, perturbations, or hypotheses. When a sufficient subset crosses a defined threshold, the program moves “forward.” By design, the loop becomes progressively exploitative.
This structure exists for good reasons. Experiments are slow. Teams need to plan. Work must be parallelized. Programs must be compared. Resources must be allocated. Staging makes discovery scalable. But it also quietly transforms the learning problem.
The process is not fully deterministic, and there is variation, especially early. But as assays stabilize, discovery increasingly behaves like local optimization of a global, complex objective, while only a few dimensions are made legible at each step.
What the system is allowed to correct — its assumptions about mechanisms, relevance, and transfer — becomes narrower.
Transferability failure
One of biotech’s persistent failures is not the lack of activity, but the lack of transferability. Compounds work in assays. They work in engineered systems. They work in animals. And then they stop working. This is often framed as a property of biology: human systems are too complex, models are too poor, translation is inherently uncertain. That is partly true. But from a learning perspective, there is another explanation.
Discovery programs are increasingly forced to approximate local optimization of a global, complex objective. They stabilize assays early, define proxy objectives, and then invest heavily in improving performance inside those abstractions. Evidence accumulates rapidly — but primarily within a fixed framing of the system.
Consider a program that has converged on a mechanistic story inside a particular experimental world: a specific cell context, a stabilized perturbation logic, and a set of readouts that reliably sort compounds. Most new experiments deepen that world. They add resolution. They improve control. They sharpen rankings. A hypothesis-threatening move would not be another refinement. It would be a decision to rebuild the experimental world itself: a different disease-relevant system, different cellular assumptions, different controls, different dominant failure modes. Such an experiment is not primarily meant to advance assets. It is meant to test whether the causal story the program has organized around can survive contact with a genuinely different biological framing.
A new readout deepens a view.
A new system challenges it.
Transferability fails when the learning system itself collapses to a narrow and fragile representation of biological reality. This is what premature consolidation looks like in discovery. In learning terms, uncertainty has been collapsed too early. The program commits to a narrow slice of the hypothesis space before the evidence structurally constrains it. It optimizes within a story faster than it tests whether the story itself can travel. From that point on, most experiments deepen confidence rather than reshape belief. They reduce variance inside an abstraction, instead of forcing incompatible abstractions to confront one another.
This is when the system first encounters biology it did not train itself to see.
Reframing discovery as a learning system shifts where value is expected to come from. Not from running more experiments. Not from moving faster through phases. But from improving how the system updates itself.
Two kinds of updates
In sequential learning systems, not all updates mean the same thing. Some refine a model. Others decide which models are still admissible. One concentrates belief. The other redistributes it. In learning terms, this is the difference between learning parameters inside a model and learning which models are still possible.
Discovery is mostly organized around the first. Measurements accumulate inside stabilized assays. Signal-to-noise improves. Rankings sharpen. Dose–response curves become precise. This is learning within a framing. It deepens a view. It reduces variance. It increases confidence in what is already assumed. In learning terms, this is exploitation.
The second kind of update is rarer and more expensive.
It introduces experiments whose primary role is not to refine a readout, but to discriminate between explanations.
- Different biological systems.
- Incompatible perturbation logics.
- Distinct failure modes.
- Independent readout regimes.
These experiments are not chosen to improve performance inside a model. They are chosen to test whether the model is even adequate. In learning terms, this is exploration. These updates do not merely validate. They restructure the learning problem. They make some hypotheses impossible. They force probability mass to move. They expose where confidence comes from repetition rather than constraint. They change the geometry of belief.
Running discovery as a genuine learning system therefore does not primarily mean adding more AI, more automation, or more throughput. It means designing feedback loops where uncertainty is not immediately collapsed, validation is not only confirmatory, stage transitions do not erase epistemic state, orthogonality is treated as exploration, and progress is measured by correction, not only advancement. This does not slow discovery. It changes what discovery optimizes.
Conclusion
From a computational perspective, scientific discovery is not a data problem. It is a feedback problem. Experiments are expensive queries. Programs are sequential decision processes. Pipelines are implicit learning systems. And today, most of those systems are built to move forward efficiently, not to preserve and transform belief. They execute science well. They update belief inside a field they no longer question. They are not structured to sustain the question of what else could be true.
The hidden engine of discovery is therefore not experimentation itself, but the structure of the loops that connect experiments across time: how abstractions are frozen, how uncertainty is collapsed, how evidence is assembled, and how belief is allowed to shape the next question.
Pipelines make discovery scalable. Feedback makes it truthful.
And as biology becomes more complex, more heterogeneous, and more human-relevant, it is increasingly the quality of those feedback loops — not the speed of any individual experiment — that will determine whether discovery actually learns.